
前面我们用Excel和Matlab实现了酶动力学的参数估算方法,今天我们介绍使用药动建模工具phoenix来进行酶动力学分析。正如我们前面提到的,phoenix不支持隐式方程的求参,所以需要对数据进行一下变通,通过观察IMM方程,我们发现,虽然C0和C1之间不能用显示方程表示,但是C1和t之间的关系却可以写成显示方程,一系列的C1和对应的反应时间t我们都知道,C0可以类比于PK中的给药剂量。这种处理方式类似群体PK,每个个体在t时间采一个点,存在大量个体,每个个体的给药剂量不同,这种稀疏的数据只能用群体的模型去估计。为了实现群体PK,这就需要用到PML,即Phoenix Model Language。PML是借鉴了C++,S-Plus中的一些规范的用于Phoenix平台的建模语言,可进行非线性混合效应(NLME)分析。NLME背后的原理理解起来有点困难,但我们作为药学人士,没必要搞懂其具体的原理,只要我们会用这门语言编写满足我们要求的模型代码即可。我的原则是,够用即可,多了不学。PML支持微分方程和显示方程,C1与t的关系用微分方程表示更简单,其实就是最常见的米曼方程: dC/dt=-Vm*C/(Km+C)
EnzymeKinetics(){
//米曼方程
deriv(C = - Vm*C/(Km + C))
//dose的位置,即初始浓度是加在C这个变量上
dosepoint(C)
//误差模型,一般是additive,看看残差分布是否随机,如果不随机,可以用multiplictive等其他误差模型
error(CEps = 1)
observe(CObs = C + CEps)
//CObs是观测值,这个不能变,其等于C加误差
/*结构参数,这个主要是用来考虑个体之间的波动,其认为存在一个群体的值,即tvVm和tvKm,而对于每个个体来说,它们又有自己特定的值*/
stparm(Vm = (tvVm) * exp(nVm))
stparm(Km = (tvKm) * exp(nKm))
//固定效应参数,即群体的均值,等号后面为初始估计值,最大和最小没有指定,就是正无穷和 负无穷
fixef(tvVm = c(, 10, ))
fixef(tvKm = c(, 10, ))
//随机效应,进行群体分析的时候,这个参数必须有,如果没有的话,RUN的时候只能选"naive pooled"方法。
ranef(diag(nVm, nKm) = c(1, 1))
}
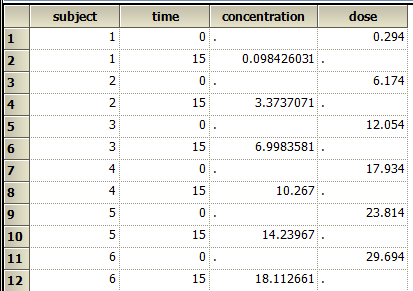
上面既为基于群体药动学理论的酶动力学分析模型,其他的模型照上面的样子稍微修改就可以实现了,一点不难吧。接下来,只要把对应的变量mapping一下, 就可以RUN了。下图为数据格式,有几个浓度,就有几个subject,0时间的浓度为空,dose那一列就是初始浓度,15分钟的浓度就是反应15分钟后测定的浓度。

由上图可知,残差在0附近随机分布,拟合的参数与理论值(Vm=5, Km=100)非常接近(也与昨天用matlab求算的结果非常接近),并且预测 的stdev0与我们模拟所用的随机噪音的方差(0.5)非常接近,可见 群体的方法,不仅可以求算准确的参数,连误差的估计都很靠谱。
–EOF–
文章来自[MS: 质谱与建模],微信号:MS4Fun,不定期发布自己在质谱应用和建模&模拟方面遇到的一些有趣的事情,欢迎分享与推荐。
