当我想好这个题目的时候,我顺便放狗搜了一下,找到几个非常对我胃口的博客(数据科学与R语言,Yihui Xie)。在看其中文档的过程中,我曾有短暂的失落感,“我在统计方面的知识太逊了”,不过我马上意识到自己又陷入了完美主义的坑,一个人怎能那方面都那么出色呢?在统计领域,我只要知道有哪些流行技术,哪些对我现在的研究课题有帮助,或者将来有帮助即可,只要分类整理入自己的笔记即可,完全可以等到需要的时候再去学。我自己喜欢的专业才是最根本的,这个是核心,其他只是点缀而已。我的目标是,“比药学家懂统计,比统计学家懂药学”!
为什么会想写这个题目呢?因为今天做酶动力学的模拟实验的时候,确实发现了这种现象,只有观测变量(因变量)的误差的方差恒定时,用非线性拟合得到的参数才是无偏的。对于线性拟合,只有满足高斯–马尔科夫定理条件时(零均值、等方差、不相关),最小二乘估计才是无偏估计。应该这对非线性拟合,同样适用吧。如果观测变量的误差不满足高-马条件时(比如方差随观测变量的增大而增大,可以从残差图上看到),该如何进行无偏估计呢?其实前几天已经提到了,正是Phoenix中的可进行群体药动学分析的PML!其所采用的技术为非线性混合效应模型法,广泛用于群体药动学参数的估计,模型中包含固定效应(相当于传统的非线性模型部分)、随机效应(个体间的变异)和误差模型(这里可以针对不同类型的误差进行建模,关键所在)。下面给出一个模拟实例,来说明用NLME进行非等方差时的参数估计。
模拟数据用EnzySolver的模拟功能来实现,具体参数如下:

模拟后的数据和误差分布如下:
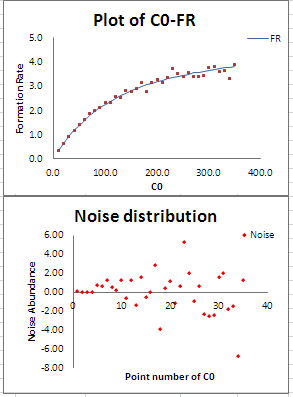
用EnzySolver自带的非线性拟合功能,求得的参数为[Vm=4.8, Km=90.7],与理论值[Vm=5, Km=100]有较大偏差,尤其是Km偏差快到10%了。将模拟的数据带入phoenix的PML模型,先假定误差模型为CObs=C+CEps (CObs观测值,C真实值,CEps误差项),拟合结果如下:
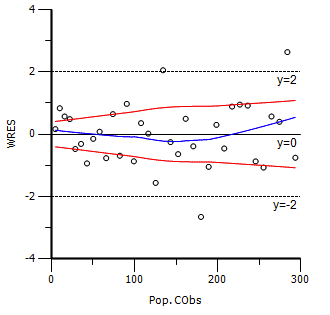
如上所求参数确有很大偏差,并且残差分布趋势随着浓度的增加而增大,这也提示所选择的误差模型不合适。将误差模型改为CObs=C+C*CEps,拟合结果如下:

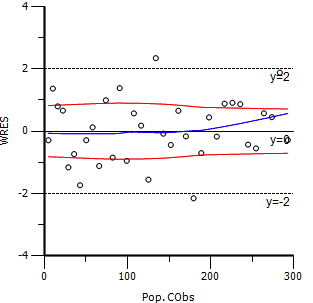
可见,在我们选择了合适的误差模型以后,所求算的Km和Vm与理论值就非常接近了,且所估计的方差0.013与理论方差0.02相当接近。
–EOF–
文章来自[MS: 质谱与建模],微信号:MS4Fun,不定期发布自己在质谱应用和建模&模拟方面遇到的一些有趣的事情,欢迎分享与推荐。

文章来自[MS: 质谱与建模],微信号:MS4Fun,不定期发布自己在质谱应用和建模&模拟方面遇到的一些有趣的事情,欢迎分享与推荐。